Can We Automate Fairness? Professor Alexandra Chouldechova on Machine Learning and Discrimination
By Scottie Barsotti
Machines are making more and more decisions for us every day—some of great importance. Heinz College faculty member Alexandra Chouldechova is laying the methodological groundwork for fairer, more transparent predictive techniques.
A judge sits at his bench, stone-faced and contemplating. He has just heard the jury’s verdict: Guilty. The defendant is a 21-year-old black man, charged and now convicted of felony grand theft and two counts of drug possession. He is a first-time offender. The judge frowns as he considers the severity of the sentence. Chief among his considerations is this question: If I show leniency now, will this man offend again in the future?
Weighing heavily on the judge’s mind is the defendant’s “risk assessment score”, a data-driven predictive score determined by an algorithm, which has seen increased usage in U.S. courtrooms.
Despite his desire to be impartial in sentencing, the score is ominous. Damning, even. 10 out of 10. The highest risk.
But what’s behind that score? And more importantly: Is it biased because the defendant is black?
What may surprise you is that systemic racism doesn’t begin and end with unequitable laws and ingrained, personal prejudices. Recent reporting has revealed that data-driven predictive models have the potential to amplify those prejudices, and such algorithms can inject greater unfairness into a system that is already slanted against certain groups.
“There are things that we’re quite comfortable with [letting a computer model decide for us], like Netflix recommends movies and Google returns search queries to us—and where would we be without them? But then, there are more questionable uses,” said Alexandra Chouldechova, Assistant Professor of Statistics and Public Policy at Heinz College.
Chouldechova is working to solve this problem with research that challenges conventional wisdom in the assessment industry and provides a framework for designing and vetting better predictive algorithms. She says while machine predictions are valuable in decision support—and research shows they are generally more accurate than human predictions—that it’s essential to ensure they are as fair (or even fairer) than humans can be.
This is especially true given the immense stakes in certain contexts, such as in criminal justice.
The investigative website ProPublica recently exposed disparities in outcomes for a recidivism assessment tool called Correctional Offender Management Profiling for Alternative Sanctions, or COMPAS, suggesting its algorithm is skewed against black defendants. The report alleged that COMPAS assigned black defendants higher risk scores overall and inaccurately predicted their future criminal behavior at an alarming rate—twice as many “false positives” when compared with white defendants, yet only half as many “false negatives.” (Northpointe, the company that owns COMPAS, has rejected the conclusions and defended its methodology.)
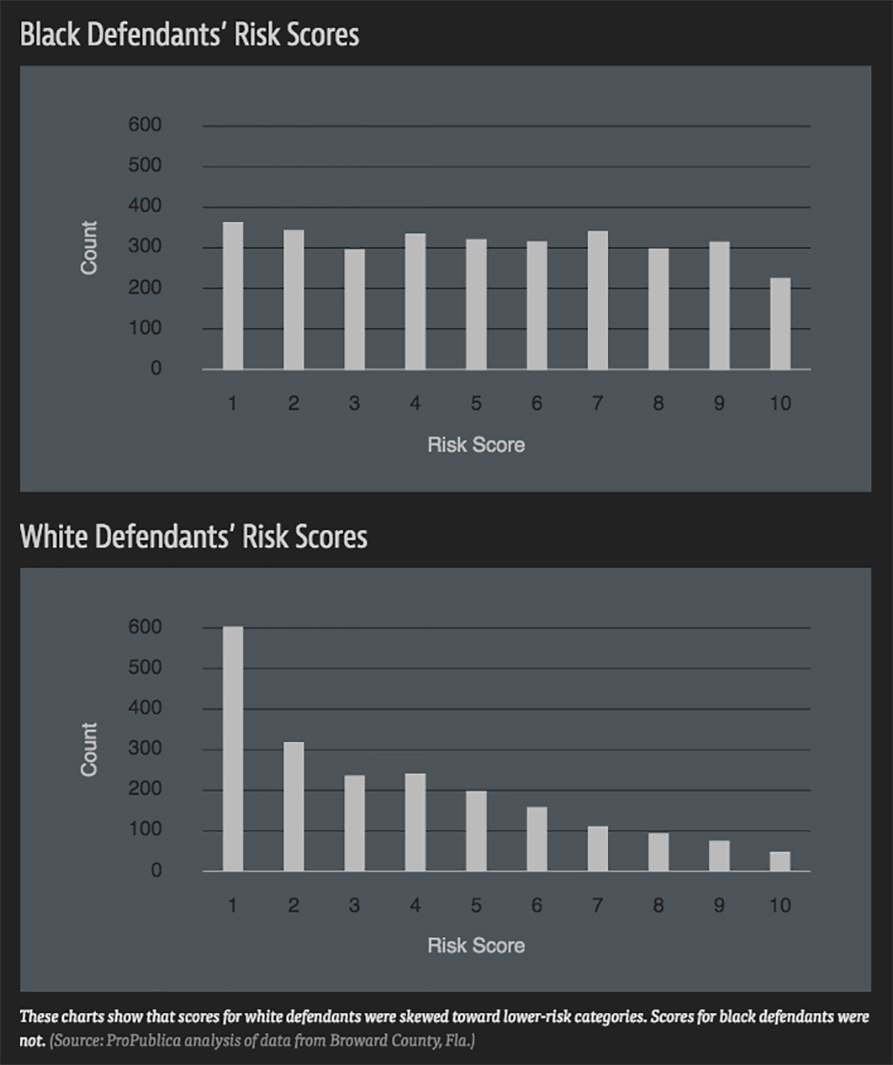
Source: ProPublica
Chouldechova says risk assessments are traditionally held to the same standards of bias as psychological and educational tests, something called “predictive parity.” While that may seem reasonable, she says it’s not adequate in all contexts. Following the ProPublica-Northpointe feud, Chouldechova performed her own analysis, which she presented at the Fairness, Accountability, and Transparency in Machine Learning (FAT/ML) 2016 conference.
What she determined is that predictive parity leads to imbalances in error rates that disadvantage some groups over others—the seemingly counter-intuitive reality that a scoring model can be free from predictive bias in design, and yet still have disparate, even discriminatory, impacts in practice.
“What it means for a model to be fair is very much an open question. There is no single notion of fairness that will work for every decision context or for every goal,” said Chouldechova. “Start with the context in which you’re going to apply [your decision], and work backwards from there.”
Acknowledging that machine bias is a real problem means that work can be done to combat it, in criminal justice and beyond. That begs the question: what does fairness truly look like in an automated world?
Criminal systems don’t over-penalize
Severity of punishments can be more uniform. Fewer false positives means shorter sentences for non-violent offenders and a thinning of the prison populations; fewer false negatives means more dangerous criminals are being correctly identified.
"Before courts adopt a new risk assessment instrument, they should examine whether doing so may introduce undesirable inequities, and whether steps need to be taken to bring error rates in balance," said Chouldechova.
The top applicants shine through
Current text-mining methods can teach machines associations that aren’t based in fact. This creates problems in automated employment evaluations, which often rely on historical decision data to predict success and can cause highly qualified applicants to be overlooked.
“Race and gender are very visible features of an individual that are proxies for the experiences they’ve had and that shape what they look like [as a candidate on paper],” said Chouldechova. She explains that an algorithm scanning a resume may not specifically conclude ‘this candidate is a woman,’ but will pick up values like what sports she played or what activities she was involved in. Those terms could be associated with ‘woman’ and thus ‘homemaker’ instead of ‘programmer’ based on biases in the data used to train the algorithm.
“Is that how we want to be ranking our candidates? Definitely not. You want to test and re-calibrate to ensure this isn’t happening,” she said.
Who you are doesn’t limit access to care
Patients need not be pigeonholed in ways that undermine their care. In the health context, Chouldechova says that a model may be over-trained on a majority group’s socioeconomic or genetic risk factors that are not applicable to patients who belong to other groups, thus causing differences in diagnosis quality or certainty.
“We need to think about what populations our model is trained on, and consider a different model or data collection scheme in order to better understand the populations where we’re not doing as well,” she said.
See the same Internet, no matter where you live
Geographic price discrimination is the practice of charging disparate rates for the same product or service based on a consumer’s location. While this is legal in the United States and some other regions, it can raise ethical concerns and make products and services unavailable to people based solely on their ZIP code.
“To the extent some companies hold themselves up as ethical entities and not just ones that operate within the bounds of the law, it’s important for them to think about these issues,” said Chouldechova. “Companies are starting to pay attention to doing this evaluation in-house, and the academic community is providing input.”
She noted that the information you see on the Internet is fully curated and customized when you request it—algorithms will use data collected from your activities to display select search results while obscuring others, and can create problematic “echo chambers” on social media. Chouldechova says that just as with decision support tools, these models can be re-trained to encourage exploration of new ideas rather than exploiting known preferences or reinforcing prejudices.
"We can do more"
It is possible to identify what criteria feed into discriminatory practices and re-calibrate models to avoid them. Chouldechova says that in addition to making predictive models more fair, they need greater transparency in design.
In the majority of cases, she suggests there is no intent to discriminate embedded within predictive algorithms, rather there is an effort to predict and classify outcomes (in itself a form of discrimination, but not one that is inherently insidious).
“I think there are very good reasons for wanting to use data-driven approaches in general,” said Chouldechova, however, she notes that predictive models are not as good at handling nuanced cases.
In other words, we won’t be saying goodbye to judges anytime soon. Rather, Chouldechova says the real task is to give them—and other decision-makers—the best, fairest information possible.
“If we’re using risk to color our judgments, then we should be doing it more accurately,” she said. “We can do more.”
The paper Professor Chouldechova presented at FAT/ML is titled, "Fair prediction with disparate impact: A study of bias in recidivism prediction instruments." Read it by following the link below.